
进阶至端到端竞赛,车企在智驾领域的段位便明显拉开了差距。其中影响因素诸多,数据量和算力是两个重要因素,也是车企在端到端时代面临的最大挑战。这背后,裹挟着车企的财力、人力与判断力。也可能过去数年的数据积累,到如今一无用处。但是没人可以置身事外,逃避就意味着被淘汰。角力智驾,端到端只是一个开始。
文 | 魏冰
编辑 | 李欢欢
运营 | 土豆
智驾,已经成了众车企不得不攻下的堡垒。
这是一个不进则退的赛场,稍不留神,就会被对手甩在身后。从2023年开启的开城之战,到如今的端到端竞赛,场上的玩家不得不绷紧了神经,不敢有丝毫懈怠。
所谓端到端,即深度学习中的概念,英文为“End-to-End(E2E)”,指的是一个AI模型,只要输入原始数据就可以输出最终结果。应用到自动驾驶领域,意味着只用一个模型,就能把摄像头等传感器收集到的感知信息,转换成车辆方向盘怎么转、油门踩多少等操作指令,让汽车自动行驶。
和传统的通过感知、规划与决策、控制三个模块体系下的智驾方案不同,端到端的优势在于,从感知到决策直接用一个大模型解决,输入传感器信号之后,系统直接发出行动指令,减少了信息在不同模块之间传递时的“损耗”和偏差。
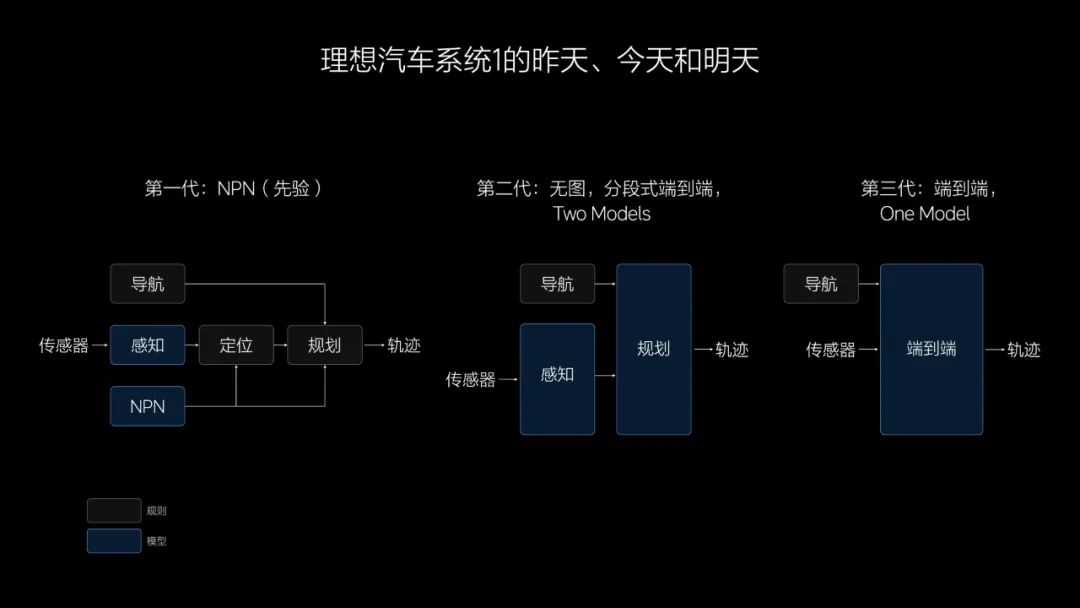
眼下,华为、蔚小理、特斯拉,甚至比亚迪和奔驰等传统车企,都在卷端到端,但各家的思路与进展,又各不相同。比如,特斯拉和理想的思路是One Model(一个大模型),在此基础上,理想又率先在业内落地了双系统——端到端+VLM(视觉语言模型),华为和小鹏则是分段式端到端。
这其中孰优孰劣?理想认为,要想向L3、L4级别的自动驾驶进阶,One Model更适合,这代表着一种更高级的迭代和研发流程,而分段式更适合做L2级别的辅助驾驶。
比蔚来和小鹏晚两年才自研智驾的理想,怎么就后来居上了?
在理想内部,有RD和PD两条脉络研发智驾,PD是产品交付研发,推送给全量用户、千人团测的版本由该团队负责,RD可以理解为“超前作业”,负责预研技术,探索理想通向未来人工智能的方向。在这样的架构下,理想的这套“端到端+VLM”的方案,只用了大约一年多的时间便完成了三代迭代。

这背后需要付出的时间与精力,旁人大概是难以想象的。理想汽车智能驾驶研发副总裁郎咸朋坦言,大家为此舍弃了“个人休息时间”,但也别无选择、没有退路,“大家都清楚公司的目标是什么”。
去年理想秋季战略会上,CEO李想明确强调,智能驾驶是核心战略,并给内部确定了时间节点,“2024年要成为智驾的绝对头部”。
除了一号位自上而下传导的压力,还有用户层面的鞭策,理想汽车智能驾驶技术研发负责人贾鹏自我调侃:“自从2020年由英伟达入职理想后,每天面临的环境就是——我们是后进生,天天被家长(用户)骂。”
这让理想如履薄冰,不得不加速追赶,且没有捷径可走。虽然已经有特斯拉提前交卷,但直接抄作业却行不通。郎咸朋与曾经负责小鹏智驾业务的吴新宙达成共识,整个过程可以加速,但不能跳过,否则会跳过对很多技术的理解。
因此,虽然时间紧急,理想还是率先尝试了NPN方案(Neural Prior Net,先验神经算法,使用部分道路和地图的先验信息,帮助车辆识别道路特征,减少对高精地图的依赖),赶在年底实现了百城NOA的Flag,但理想发现“只要用图就做不了全国落地”,因为偏远城市的车不多,数据迭代就有问题,而这些归根结底都是受到了地图的限制。
意识到问题,理想快速切换到无图方案。不过无图模式对资源的消耗很大,这种方式有解决不完的Coner case,郎咸朋解释:“我什么时候超车变道?是前面车压我30公里时速时,还是20公里时?在某个速度条件下,旁边有实线我变不变?旁边有车我变不变?后边来车变不变?”Coner case的场景是无穷无尽的,但“边界是显而易见的”(依靠处理Coner case来解决极端场景的能力是有限的)。
到了这一步,端到端便摆在了理想面前。郎咸朋表示,理想不是为了端到端而做端到端,理想的智驾方案迭代,是“把技术全都做完一遍之后,遇到问题解决问题的一个实事求是的过程”。对手的进程不太会影响理想,李想强调,用户体验才是做决策的衡量标准。
在这个过程中,理想渐渐摸索出自己的思路。
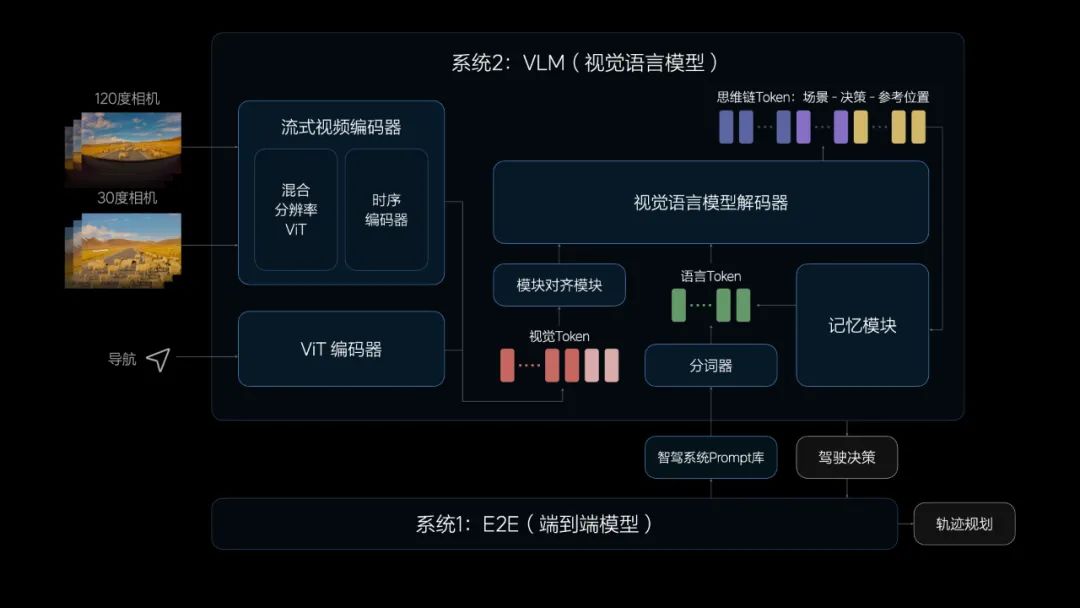
在天津实测的时候,郎咸朋发现天津的红绿灯是进度条式的,和其他城市的红绿灯不太一样,怎么让系统理解新的场景?这需要让系统获得逻辑推理的能力。在这个时候,理想看到了双系统理论。
于是,理想在端到端模型外,连接了一个VLM (视觉语言模型),这样便形成两个系统,系统一负责行驶过程中及时的响应处理,系统二用来解决复杂的需要逻辑推理的问题。
端到端能否做好,主要影响因素是数据和算力。
今年初,特斯拉正式在北美推送FSD V12,理想智驾团队曾远赴美国体验该系统,总结下来,“特斯拉FSD在美国西海岸的体验确实很棒,不过到纽约之后性能急剧下滑”,这可能和数据量有关。
在这方面,郎咸朋表现出绝对的自信。一方面,理想是增程车,没有里程焦虑,偏远的地方都能去,所以数据分布足够广。另一方面,被外界诟病的“套娃造车”,郎咸朋却觉得对自动驾驶来说是一种优势,所有的摄像头规格、安装位置都是一致的,数据量非常充足且可以复用。
海量的数据,也不是拿来就能直接用,需要筛选出优质数据,喂给系统,好让系统迅速学习、成长。理想建立了一套自己的数据筛选标准——“老司机”,按照驾驶安全情况、驾驶风格等维度对80万车主进行筛选,只有不到3%的车主通过了考核。在这套标准下,从12亿公里的原始数据里只能筛选出几千万公里的数据。
除了数量和质量,数据的配比也会影响大模型的学习效果。郎咸朋和团队曾经发现,在等红绿灯的时候,系统总想并线、加塞。研发人员觉得很奇怪,他们从没给系统输入这样的数据。后来发现,是因为他们把用户长时间等红灯的数据删除了,所以系统没学会等红灯,混淆了等红灯和堵车时的场景。补充这部分数据后,问题消失了。
时间来到2024年8月,车企在智驾赛道的角力异常激烈。大约一个月前,蔚来正式宣布量产端到端AEB(紧急制动功能),一周前,小鹏在AI智驾发布会上强调,除了特斯拉,只有自己实现了端到端量产落地。不曾想,几天后,华为在享界S9实测中率先秀出了“车位到车位的端到端”能力。

但这只是一个开始,智驾是一场费时费力的马拉松,没有一定资本,甚至上不了赛道。
毕竟,在数据之外,影响端到端效果的另一个因素——算力,需要数额不菲的资金做后盾。据郎咸朋透露,目前理想有1.5万张等同于A100、A800算力的GPU,每年光是在租卡上就要投入10亿人民币,但这还远远不够。将来,理想预计花在这方面的费用将高达每年10亿美元。
“如果你一年拿不出10亿美金训练系统,可能会在将来的自动驾驶竞争中被淘汰。”理想很清楚,在卷向自动驾驶的过程中,会拖死一批友商。
以下是理想汽车智能驾驶副总裁郎咸朋、理想汽车智能驾驶技术研发负责人贾鹏与每人Auto等对话的问答节选(在不影响原意的情况下,有删改):
用系统一还是系统二,将来大模型自己决定
问:为什么要切换至端到端?
郎咸朋:去年一年我们做了三代技术研发,从最开始的高速做到城市,城市里面我们先是用了NPN方案。今年年初我们从“百城”切换到无图,在做无图的过程中,我们意识到无图的能力是有上限的,如果再继续做这个方案,就需要很多人和资源,去设计场景、实现场景、测试场景。
从无图再迭代到现在的端到端方案。在这个过程中,我们发现这套方案对后期的L3、L4级别自动驾驶来说,有一个非常大的问题,就是遇到新的场景没办法正确处理。举个例子,天津的红绿灯是进度条式的,和其他地方灯泡或者倒计时类型的红绿灯不太一样。人类可以轻松识别,它就是红绿灯,并且根据红绿灯的指示,正常的停止启动。
我们需要让系统也有这种对场景的理解能力,在这个时候我们看到双系统的理论:快系统做出及时的处理响应,慢系统对应复杂的思考和逻辑判断,双系统共同组成了人类认知和思维的机制,我们就想这套系统的理论怎么运用到自动驾驶上,最终选择了端到端模型来实现系统一,系统二用VLM的视觉语言大模型来实现。
问:系统一和系统二如何分工?
贾鹏:我们是两个模型,有两颗Orin-X,一颗是跑端到端,模型相对小一些,大概三四亿的参数量,然后跑到十几赫兹,会高频地控车,因为要实时控车。VLM虽然参数量大,但也不能一两秒控一次,现在我们把它优化到大概三四赫兹的准实时水平,大概三百毫秒的延迟。系统每时每刻都在做决策,输出两个决策,比如一个是让行减速还是避让,然后第二个会给出参考的轨迹,比如说是朝这条车道还是朝那条车道开,这两个信息都会直接喂到模型里,然后同时出结果,大概是这么一个结构,系统一并不是完全采纳系统二的意见,系统二是增强系统一的决策。
L3阶段的自动驾驶,系统一发挥主要的作用,系统二只是一个参考或者咨询特殊情况,到L4的时候,系统二发挥作用会更多,不是说系统二时时刻刻都在控车,而是它真的在发挥非常重要的决策和判断作用,在一些未知场景下,系统二的能力决定了能不能到L4,但系统一的基础能力是L3的必要保障。

问:未来两个系统会合二为一吗?
贾鹏:这是我们在预研的下一步,现在的想法是量产的还是两个模型,目前无图6.0已经全国都能开了,我们想端到端+VLM这套东西可以做到全国都比较好开,那再往后,到底怎么做一个量产级的L4,我们的思路是把模型的规模变得更大,容量更大,同时帧率变得更高。有机会是不是这两个模型可以合一,是走系统一还是系统二让模型自己去决定。所以如果将来有更大的算力芯片,有更好的平台,这套系统可以发挥极大的作用。
问:后悔做NPN吗?
郎咸朋:不后悔,无图有图这些东西不去做,是领悟不到这些技术的一些特点的,技术研发就是踩坑的,踩了坑就赶紧往外爬。有些友商就是做了一套东西舍不得丢掉,就掉坑里了。
问:理想的端到端技术和友商相比,优劣势在哪?
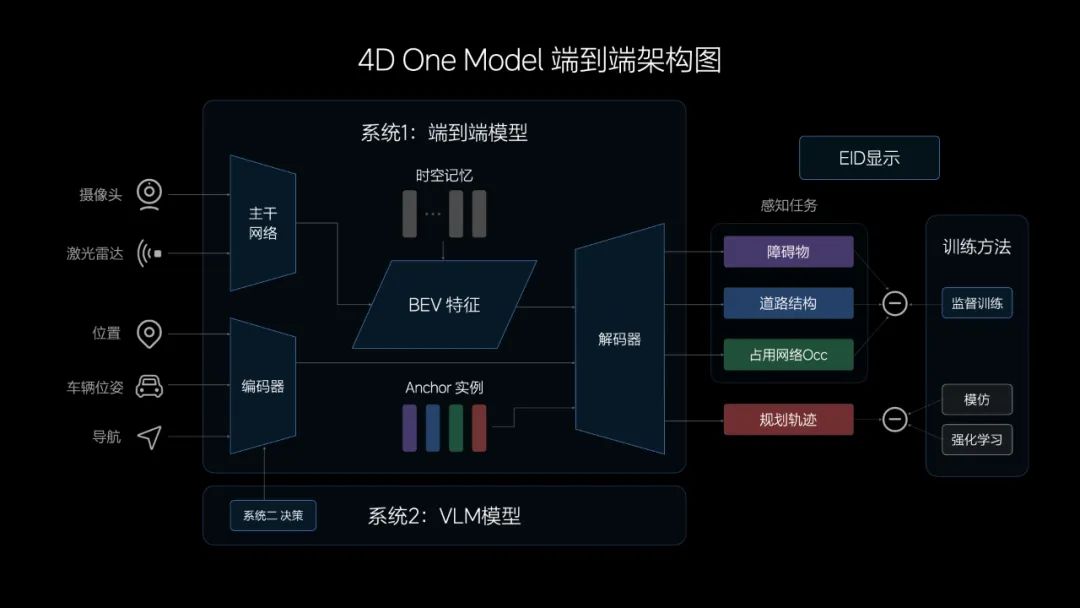
郎咸朋:我们的双系统端到端有一些独特的地方。首先,我们的端到端模型是第一个One Model的端到端模型,跟其他友商采用的分段式有很大区别。第二,我们的VLM模型是第一个能在车端部署并且量产的模型,其他的模型可能在他自己的训练集群上做训练和测试,但真正用Orin-X这种量产的车端芯片去优化并且部署到车上,我们是第一个。而且这个模型足够大,有22亿的参数量,这已经是一个实际意义上的大模型了。这套双系统也是我们第一个提出来并且落地的,从系统架构到系统实施上。
问:小鹏跟华为都是分段式的端到端?
郎咸朋:根据公开资料来看是这样的。
问:要做端到端,会面临哪些挑战?
贾鹏:我们做了一段时间端到端之后,发现非常重要的就是它的数据配比一定要做到均衡,不能因为北京上海的用户多,数据就加得多,而应该按照场景去均衡配置。因为对于Orin-X平台来说,它能支持的模型的上限可能也就三四亿参数,我能跑到十几赫兹就是它的天花板,但这1000万数据我怎么去匹配?新疆放多少,北京放多少,雨天放多少,雪天放多少,这其实要花精力去研究这件事。这是端到端时代大家面临的一个最大挑战。
1000万肯定不是在某个城市或者某个场景。所以说训练也是非常重要的,我们现在在持续探索和迭代阶段,同时多版模型是在一起训练的,你的算力如果足够大,同时可以训练多版模型。
问:端到端拼的是什么?
郎咸朋:一是有没有足够多高质量的数据;二是有没有与之匹配的充足的训练算力的集群。
问:有车企苦恼,以前的数据在端到端时代有很多用不上,他们得拆以前的桥,同时搭新的桥,又要建能够检验它的安全体系,你怎么看这个问题?
郎咸朋:在我看来,他这句话前后矛盾,他是说数据不那么重要,但又暗涵数据很重要。我第一次跟李想谈话的时候,他问我你觉得实现自动驾驶最重要的是什么?当时很多人觉得是人才和资金,我和李想的想法非常一致,我们都觉得是数据,没有数据,将来算法的训练也好,验证也好,都没有基础。
我们从2019年交付第一辆车开始,去积累数据并且搭建我们的数据平台。大家都吐槽我们在套娃,但套娃对自动驾驶有极大的好处,所有的摄像头规格和安装的位置都是一致的,这些数据我们完全可以复用。其它车企有轿车,有SUV,可能传感器也不太一样,所以对他们来说确实是个挑战。
问:现在国内车企在端到端这条路上是在同一起跑线吗?
郎咸朋:国内厂商在端到端是同一起跑线,如果是看One Model的话,可能我们会领先一些。在One Model的基础上,我们首先发布了自己的鸟蛋版本,而且是千人规模这样一个比较大量的发布和交付,大家在使用过程中也切身体验到端到端与之前无图方案相比,在性能和体验上的提升,这是我下判断的基础。
每年拿不出10亿美元,玩不了智驾
问:理想怎么筛选数据?
郎咸朋:我们的产品团队和主观评价团队都是老司机,这些人开车的经验非常丰富,按照驾驶安全情况、驾驶风格等维度对80万车主进行筛选,只有不到3%的车主通过了考核。
问:理想筛选出的数据,是绝对正确的?
贾鹏:我觉得还是幻觉问题。我们去压制幻觉,其实取决于后面GPU的部分怎么去加入这种惩罚数据,跟教育孩子是一样的,你教育多了他就不犯错了,主要取决于最后做的好不好。
问:理想有多大算力,来支持端到端研发?
郎咸朋:理想目前有等同15000张A100、A800算力的GPU。

问:理想每年在算力上的投入有多少?
郎咸朋:理想租卡一年要花费10万人民币,未来可能需要10亿美金每年。
问:需要多大算力储备,才能拿到未来的入场券?
郎咸朋:现在理想实践下来,一年10亿人民币的算力花销,这是一定要有的。否则,要不迭代速度慢,要不产品竞争力不足,未来我们觉得可能10亿美金一年是必须要有的算力投入。
我们自己也大概估算过,现在大概有15000张卡,已经挺紧张了,天天协调卡怎么分配,但是随着模型参数量的增长,我觉得至少需要3-4倍的算力,因为算力本身就提升了很多,那么它带宽存储都提高很多,约10万张A100对应的可能是30亿flops的算力。
问:端到端要正式推送给用户的标准是什么?
贾鹏:我觉得还是用户体验。我们为什么要有千人早鸟版本,而不是自己去设定一些接管目标,我觉得如果千人用户和万人用户,他们体验都挺好,就可以推,或者是超越无图版的体验也可以。
问:从后进生到提前交卷,理想做了什么?
郎咸朋:一是组织能力;二是效率,理想一直锻炼自己快速执行的能力;还有一点,就是我们5年来对数据驱动的工具链的建设。这个非常关键,即使现在有算力又有数据,如果没有一个完整高效的工具链或者数据系统,就无法高效运转。
问:理想的目标是今年要成为智驾绝对头部,怎么定义绝对头部?
郎咸朋:最终还是看量,今年我们的AD MAX的车销售数量是否在市场上是领先的?这是最硬核的指标。我只看MAX版本的销量。
我们从6.0到端到端这一个月以来,进店量更多了,销量也提升了十几个点,这就证明用户在实打实地为你的技术买单,这是最有说服力的。
理想只落后特斯拉半年了
问:之前说,理想的产品体验落后特斯拉半年,这个结论是怎么推演出来的?
郎咸朋:从特斯拉FSD V12.3开始,我们定期去美国测试。基本连续试了一周,西海岸东海岸都试过,感受下来,特斯拉在美国西海岸确实表现很棒,因为数据是最多的。但到了东海岸就会发现性能急剧下滑,尤其到了纽约之后基本MPI到10、11左右,其实跟咱们现在在国内开基本没什么太大差别。但即使是纽约,你会发现它比上海、广州的复杂程度还是差很多。另一方面因为特斯拉可以获得很多国内没有的信息,是建在了很好的基础之上,才能做到这个体验,所以我们做出了这样的判断。
问:要达到特斯拉的这种所谓行业公认的能力,需要投入和他们一样的算力?
郎咸朋:也不是非要看特斯拉,只是说在过程中遇到问题解决问题。其实就两点,一个是有充足的数据,一个是充足算力,这是建立在我们的模型参数的基础上,加上我们现在是两三个亿的端到端加22亿的VLM,将来可能随着下一代芯片的扩展,参数量还会增大,特斯拉已经到百亿参数量级,是我们的5倍,5倍的数据,算力也要成倍增加。
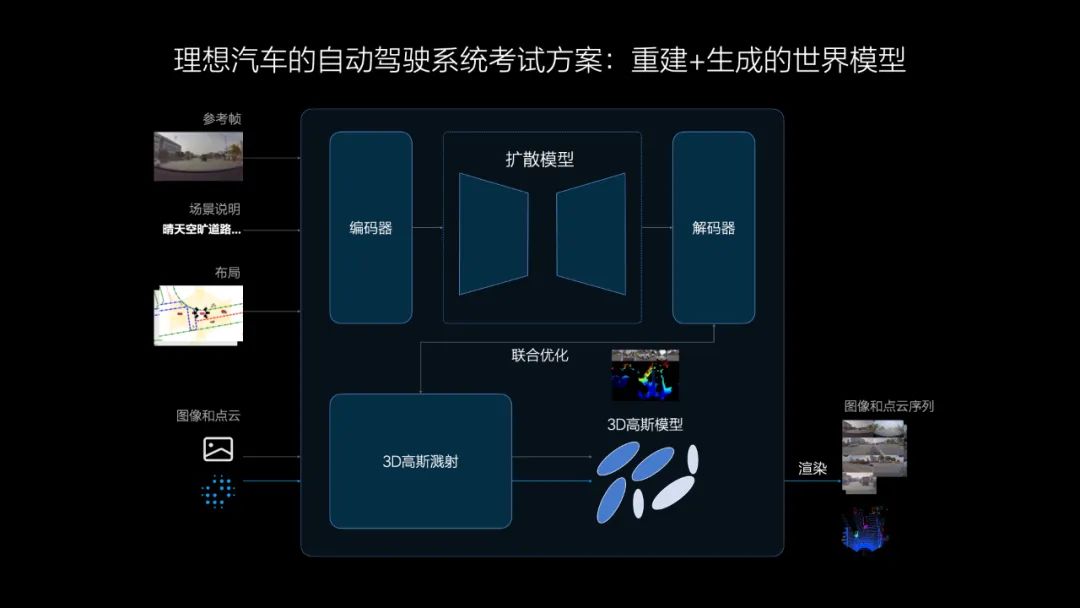
问:特斯拉是走纯视觉路线,理想保留了激光雷达,激光雷达是未来实现自动驾驶的必须配置?
贾鹏:激光雷达就是一个传感器,最大的作用是在安全上加分,这个安全不仅是对自动驾驶系统,在人开车的时候也可以提供安全,比如主动安全AEB、紧急转向AES等。激光雷达相对于视觉方案安全系数更高。我们把激光雷达看作安全带一样的配置,以后可能是车的标配。
问:业内认为,目前跑在最前面的是特斯拉和比亚迪。在下半场竞争中,会有什么样的格局呈现?
郎咸朋:上半场是电动化,下半场肯定是智能化,接下来大家会看到我们在智能化方面的投入和表现,端到端只是一个开始。
文章为每人Auto原创,侵权必究。


全部评论 (0)